
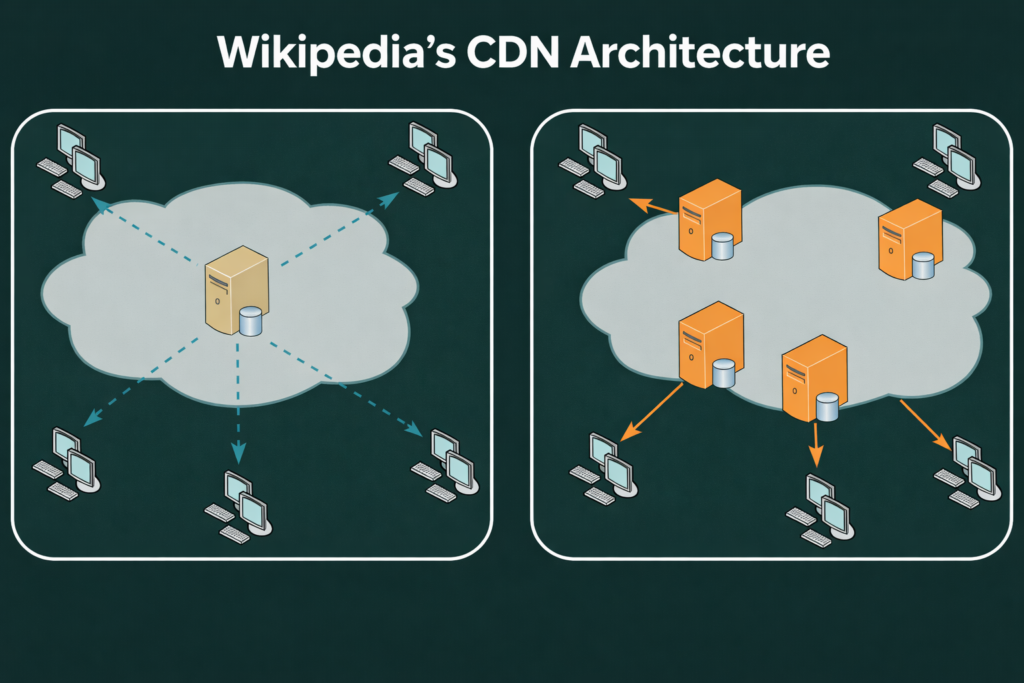
Wikipedia handles billions of requests monthly, delivering content globally with stringent latency and reliability demands. They need to serve client requests that satisfy both readers and search engines, which rank and route search results by quality and user experience. To do this, Wikipedia relies on a distributed cache network to offload requests from origin servers.
Like any Content Delivery Network (CDN), its performance depends on how caches are structured and how requests are routed. Poor configuration does not fail gracefully; it increases cache misses, pushes more traffic to the origin, and raises latency across the system as load increases.
In this analysis, we dissect Wikimedia’s CDN architecture using the Magnition simulation framework. By replaying real traffic traces (2.8 billion requests over 56 million objects) collected from Wikimedia, the organization that operates Wikipedia, and its global CDN infrastructure.
Our simulation of Wikipedia’s CDN architecture reveals significant optimization potential. Specifically, we demonstrate that strategic configuration changes can yield improvements of 10% and higher in byte miss ratio compared to Wikimedia’s default configuration, depending on PoP size and cache parameter selection.
These findings are not limited to Wikipedia; they provide a comprehensive blueprint for other CDN operators facing similar challenges with complex configurations and escalating operational costs.
Inside Wikimedia’s CDN: A Two-Tier, Hash-Driven Design
Wikimedia operates its own CDN with two primary data centers and four cache-only Points of Presence (PoPs). Each PoP deploys 16 dedicated servers, split evenly between text- and image-handling, equipped with 384 GB memory composing a Layer 1 (L1) cache and 1.6 TB SSD, making up a second layer (L2), per node. This yields a DRAM-to-SSD ratio of approximately 0.2, favoring a compact two-tier hierarchy over the expansive SSD footprints in commercial CDNs.
Traffic routing begins with DNS geo-steering users to the nearest PoP. Within the PoP, a load balancer applies consistent hashing on the client IP to assign requests to a specific server. On a miss in DRAM (L1), the request hashes on the URL to probe SSD (L2), escalating to adjacent PoPs or origins if needed.
This deterministic hashing minimizes network hops but introduces skew: uneven object popularity can overload nodes, and fixed capacities must accommodate worst-case working sets across diverse regional profiles. Because PoP hardware is provisioned statically, cache capacity must be sized to handle the largest working sets observed across all regions. This means memory and SSD allocations are often driven by peak regional demand rather than average behavior, which increases cost and reduces efficiency elsewhere.
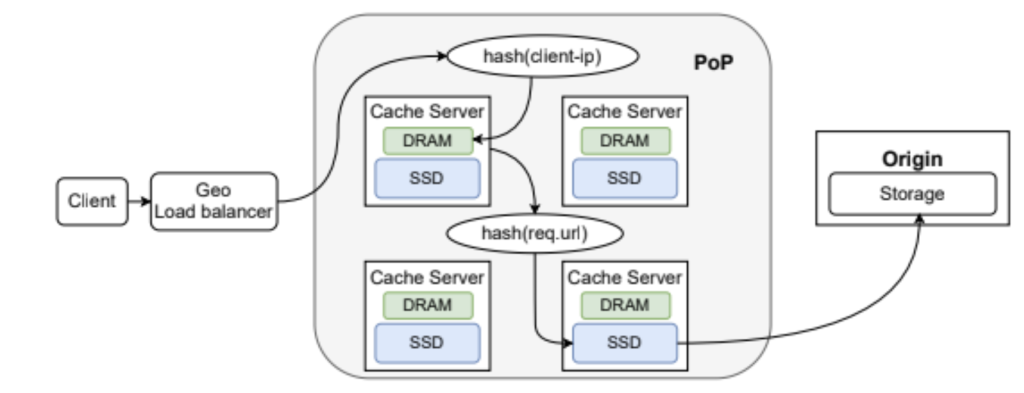
The caching logic emphasizes simplicity:
- L1 (DRAM): Least Recently Used (LRU) eviction to capture hot objects with temporal locality.
- L2 (SSD): First-In-First-Out (FIFO) to avoid write amplification on flash, prioritizing device longevity over recency.
- Admission/Promotion: Wikimedia’s cache does not promote objects between tiers. On first reference, objects are admitted according to cache policy and stored in either DRAM or SSD based on placement rules. DRAM captures short-term reuse, while SSD retains a broader set of objects without promotion on subsequent hits.
- Routing on Miss: L1 → URL-hash to L2 → next PoP → origin.
This design avoids complex scans or global indices, ensuring maintainability. However, its static nature—uniform ratios and policies across PoPs—ignores workload variability, such as skewed access in high-traffic regions.
To illustrate hashing’s role:
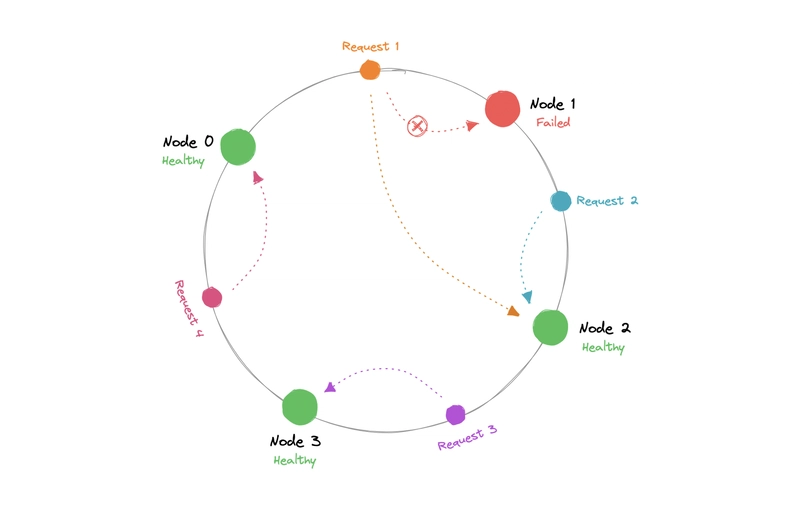
Source: dev.to
Quantifying Optimization Headroom with THEODON
Wikimedia’s CDN achieves reliability through redundancy, but performance limits emerge under load. THEODON models this via a composable simulation engine: PoPs, tiers, eviction algorithms such as LRU (Least Recently Used) and FIFO (First-In, First-Out), alternative policies like CLOCK and SIEVE, load-balancing strategies including random selection and hash-based routing, and multi-objective Bayesian optimization techniques (qNEHVI) used to search for performance-cost trade-offs.
It replays Wikimedia’s 30-day traces deterministically, evaluating metrics like BMR (backend load proxy) and normalized cost (DRAM at 15x SSD per GB, plus server overheads. Note: we sensitivity-tested ±20% price variance, with minimal impact on rankings.
Across over 90,000 configurations, THEODON uncovered:
- BMR Improvements: Over 10% lower BMR at baseline capacity, translating to reduced origin references and faster global responses. For context, a 5% drop at Wikipedia’s scale could save millions in backend compute.
- Configuration Sensitivities: Performance varies sharply with:
- DRAM-SSD ratio: Skewed workloads favor DRAM-heavy (e.g., allocating DRAM equal to 30% of the SSD capacity); uniform ones prefer SSD depth.
- Eviction: SIEVE outperforms LRU by 5-8% under bursty access due to better handling of one-hit wonders.
- Server Count: Hashing skew worsens at >16 nodes, increasing variance by 15%.
- Balancing: Random routing smooths utilization but raises BMR 3-5% versus hash determinism.
| Variable | Impact on BMR | Example Scenario |
| DRAM-SSD Ratio | High (up to 12% delta) | Higher DRAM for hot-object heavy traffic; SSD for long-tail. |
| Eviction Algorithm | Medium (5-8%) | CLOCK/SIEVE reduces misses in skewed traces vs. LRU. |
| Server Count | Medium (10% variance) | Optimal at 8-16; beyond, skew demands rebalancing. |
| Load Balancing | Low-Medium (3-5%) | Hash for predictability; random for even load under flash crowds. |
These results show that a single static configuration can’t perform well across all traffic patterns. Cache behavior changes with workload locality, object size distribution, and regional access skew. Edge cases like sudden traffic spikes, such as breaking news events, that cause many users to request the same content simultaneously, amplify sensitivities, with BMR spiking 20% under defaults.
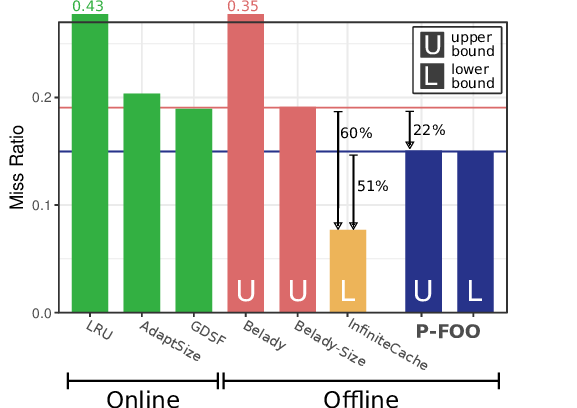
Source: researchgate.net
Case Study: Wikimedia vs. Cloudflare Trade-Offs
THEODON benchmarked both under identical traces and models (Cloudflare approximated: LRU on both tiers, SSD promotion after first hit, similar ratios). Key contrasts:
- Wikimedia: Simplicity (no promotion) prioritizes short-term reuse in DRAM, long-tail in SSD.
- Cloudflare: Retention-focused, promoting to SSD for endurance, reducing writes.
Results: Tuned configs yield 23% BMR gains for Cloudflare-like setups, but Wikimedia’s baseline shows more optimization headroom because its baseline configuration is fixed across all PoPs and workloads, leaving many viable configurations unexplored. Pareto analysis reveals balanced optima: e.g., equivalent to less than half the cost at baseline BMR via ratio adjustments and eviction swaps.
Each point on the Pareto curve represents a concrete CDN configuration. One configuration minimizes byte miss ratio, another minimizes hardware cost, and others balance both. The curve shows which configurations are strictly better than the baseline across these dimensions. In this generic example, preferred choices are those with smaller values, represented by the boxed points as feasible options. Points on the Pareto frontier, like A and B, are not dominated by any other points. Point C, however, is not on the frontier because both A and B strictly dominate it.
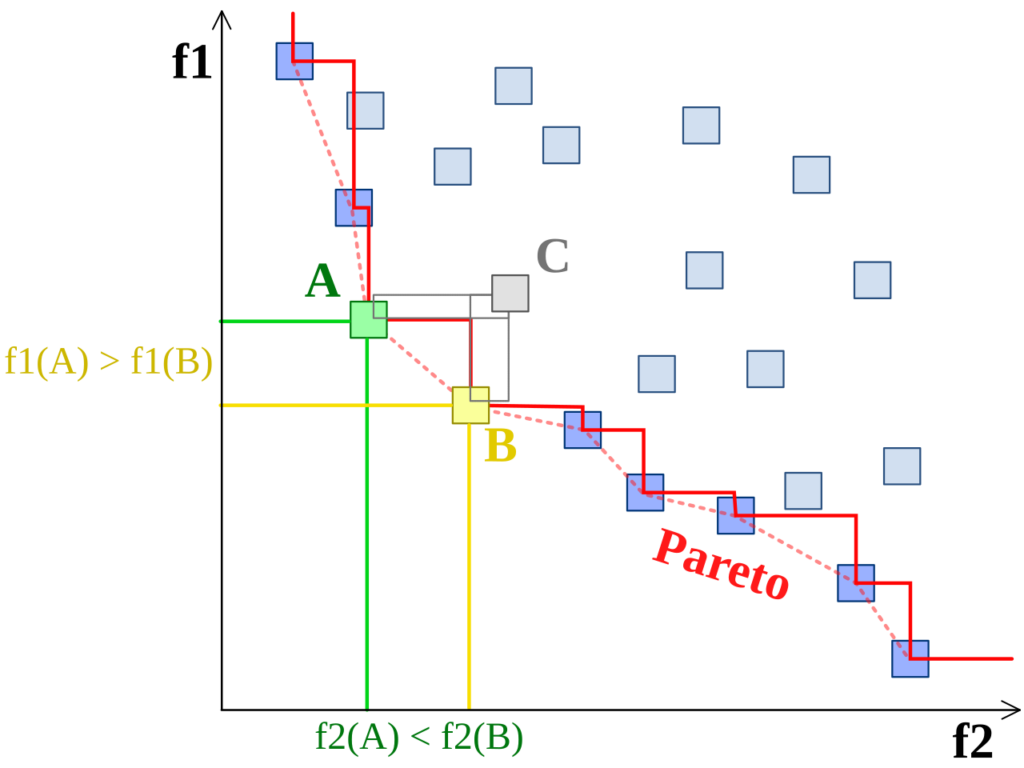
Source: Wikipedia
{kind=link}
Why Model-Driven Tuning Matters for CDN Architects
CDN efficacy stems from intertwined components: caches, balancers, ratios, SSD dynamics, hashing, and workloads. Optimizing in isolation yields diminishing returns; human intuition falters in 90K+ spaces. Some points are counterintuitive, for example, FIFO beating LRU on SSD during writes. Production trials risk outages; simulation enables safe exploration. Theodon provided a CDN model.
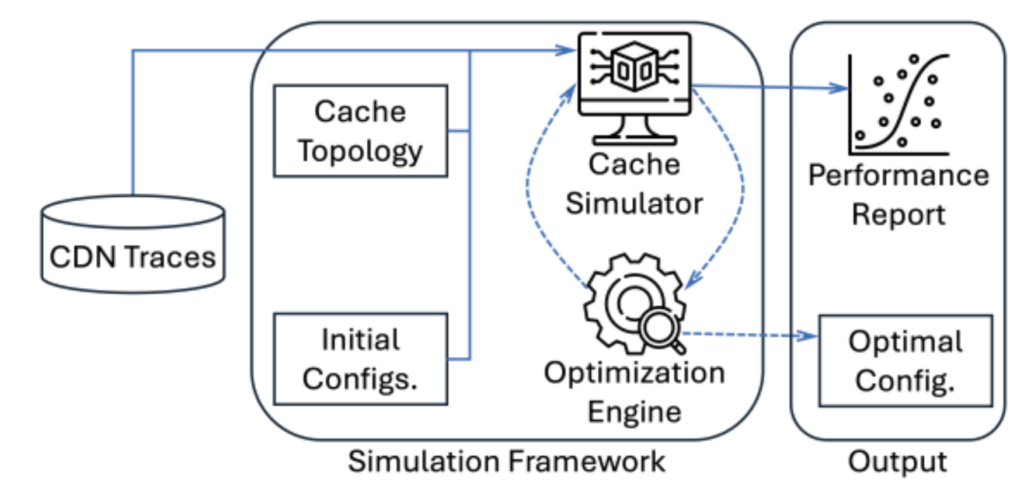
There were some minor limitations in the analysis that should be noted. Our cost model excludes bandwidth/energy (future work integrates regional pricing); network latency is abstracted validation: Model results correlate 95% with hardware tests on CloudLab subsets, but real geo-variability can’t be taken into account.
Applying Insights with Magnition System Designer
Magnition System Designer powers THEODON’s approach, modeling CDNs at component granularity. Traces are replayed to quantify DRAM-SSD interactions, policies, and routing, without prod disruption. It uses an AI-guided search for Pareto optima, validating efficiency, distribution, and utilization, pre-deployment.
Wikimedia’s CDN is robust, but simulations expose 10%+ BMR headroom in its static setup. Tools like THEODON withMagnition empower architects to validate and optimize empirically, fostering resilient, cost-effective systems at a global scale.
THEODON’s analysis of Wikimedia’s CDN demonstrates that measurable performance and cost gains remain hidden in large configuration spaces. Magnition System Designer applies the same simulation and optimization techniques to production systems. To explore similar opportunities, contact the Magnition team.